
As large language models (LLMs) continue to shape the future of artificial intelligence, having a shared understanding of the core terms is more important than ever.
Whether you’re a product manager, AI developer, or just someone curious about how these models work, this quick primer covers the essential concepts you need to know — broken down into five key areas.
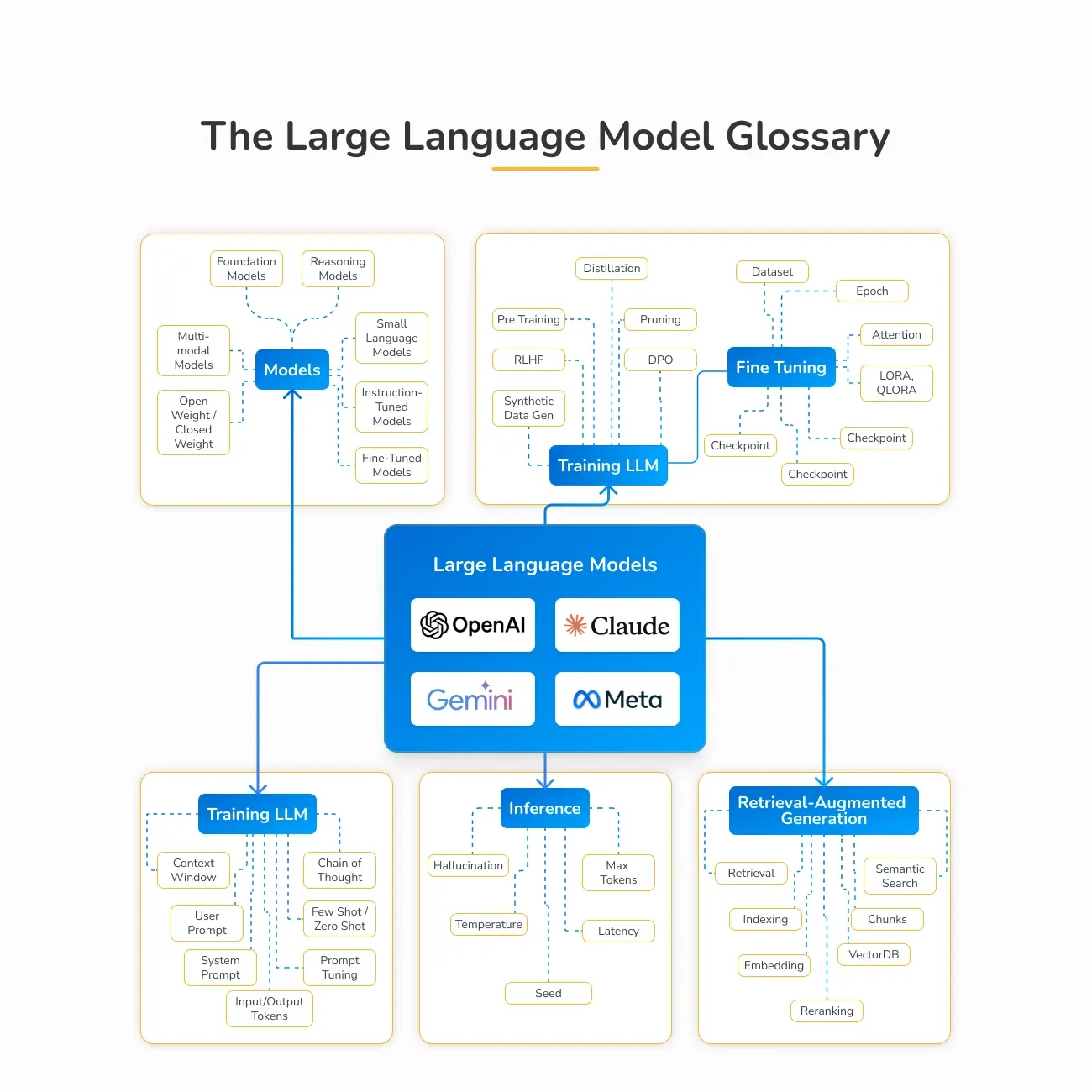
1 – Types of Language Models
Before diving into how these models work, it’s important to understand the different kinds that exist:
-
Foundation Models: These are the base models like GPT or LLaMA, trained on massive datasets to understand language.
-
Instruction-Tuned Models: These models are fine-tuned to follow specific commands, making them more responsive to user inputs.
-
Multimodal Models: These handle more than just text — they can understand and generate images, audio, or even video alongside language.
-
Reasoning Models: Designed for tasks that require logic and problem-solving, such as math or structured decision-making.
-
Small Language Models (SLMs): Lighter models built for speed and efficiency, perfect for mobile or low-power devices.
2 – How LLMs Are Trained
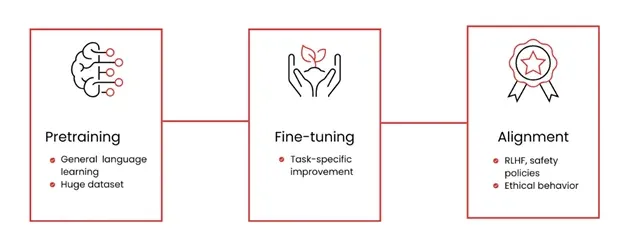
Language models learn in stages, from general understanding to specific tasks:
Pretraining: This stage uses large datasets (often synthetic) to teach the model general language patterns. Techniques like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are used to improve model behavior.
Fine-Tuning: This stage tailors the model for specific use cases. Tools like LoRA and QLoRA allow for efficient updates without retraining the entire model. Fine-tuning also includes setting up checkpoints and filtering data for quality and safety.
Alignment: This final step ensures the model behaves responsibly and ethically. It involves applying safety guidelines, value alignment strategies like RLHF, and policy constraints to align outputs with human expectations.
3 – Prompt Engineering
Prompts are how we talk to LLMs — and how we guide them to give better answers:
Prompting Techniques: Chain-of-Thought (step-by-step reasoning), Few-Shot and Zero-Shot learning (using examples or none at all), and Prompt Tuning (custom prompt templates).
System vs. User Prompts: System prompts set the behavior or rules, while user prompts are the direct instructions or questions.
Context Windows: The bigger the context window, the more the model can "remember" in a conversation — allowing for richer and more coherent replies.
4 – Inference and Generation
This is the phase where the model actually produces text based on your input:
Core Settings: Temperature (controls creativity), Max Tokens (response length), Seed (randomness control), and Latency (speed).
Watch Out for Hallucinations: Sometimes models sound confident but get facts wrong. Always verify when accuracy matters.
5 – Retrieval-Augmented Generation (RAG)
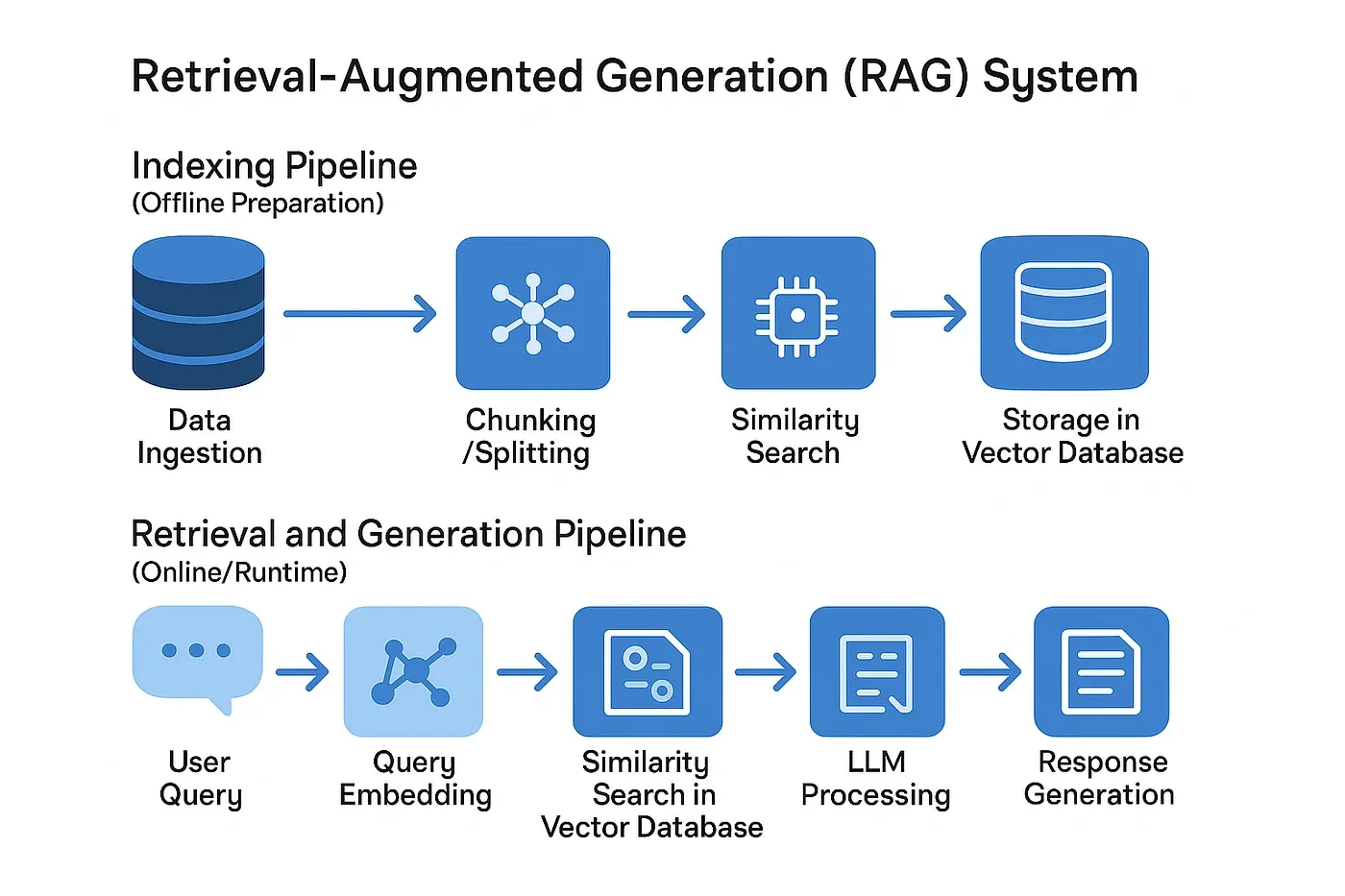
To make models more accurate and fact-based, RAG combines real-world data with language models:
Retrieval-Augmented Generation (RAG) boosts the performance of language models by connecting them to external data sources — making responses more accurate, current, and grounded in reality.
Instead of relying solely on what the model was trained on, RAG allows it to retrieve relevant information from a knowledge base at the time of answering.
Here’s how it works:
🔍 Semantic Search: Helps the system understand the meaning behind your query, not just the keywords.
🧠 Embeddings: Convert text into numerical formats that can be compared and searched efficiently.
🧩 Chunking: Breaks down documents into smaller, searchable pieces for more precise retrieval.
🗃️ Vector Databases: Tools like FAISS or Weaviate store and search these chunks quickly using similarity scoring.















