
IBM is rewriting the rules of efficiency in large language models with the early release of Granite 4.0 Tiny Preview — a pint-sized powerhouse in the upcoming Granite 4.0 family.
Despite being in the early stages of training, this model is already showing signs of punching well above its weight class, delivering performance close to that of its predecessors while slashing memory and compute demands.
What makes Granite 4.0 Tiny remarkable isn't just its size — it's the architectural innovation under the hood.
With only 2.5 trillion training tokens processed out of a planned 15 trillion, the model is already rivaling IBM’s Granite 3.3 2B Instruct in output quality — and is expected to match the Granite 3.3 8B Instruct once fully trained.
Better yet, it can run long-context (128K+) sessions on sub-$350 GPUs, making it one of the most accessible models of its kind for open-source developers.
Mamba, MoE, and NoPE
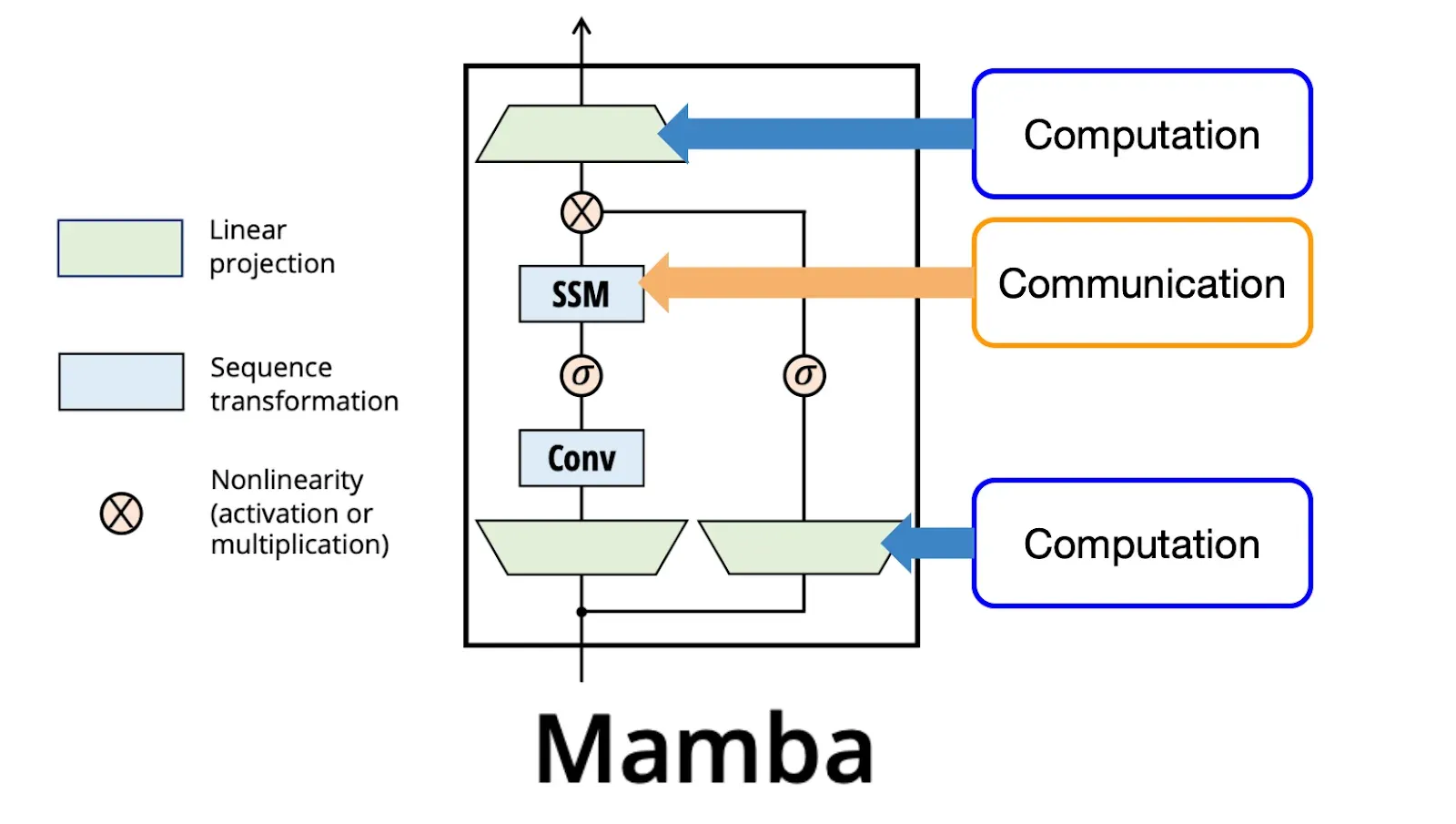
At the heart of Granite 4.0 is a hybrid architecture that blends the linear efficiency of Mamba with the contextual nuance of transformer blocks.
This isn’t a simple mix-and-match — IBM’s team, in collaboration with Dao, Gu, and researchers from UIUC, has orchestrated a finely tuned Mixture of Experts (MoE) design.
With 9 Mamba blocks for every transformer block, the architecture leverages Mamba’s ability to maintain a running summary of context, cutting memory usage and compute cost, while transformers handle more complex attention tasks.
-
7 billion total parameters, but only 1 billion are active at inference, due to a 64-expert Mixture of Experts (MoE) setup.
-
This MoE layout provides fine-grained control and efficient performance.
-
Granite 4.0 Tiny uses No Positional Encoding (NoPE) — skipping traditional methods like RoPE.
-
Why it matters: RoPE and similar encodings often fail on longer sequences, but NoPE allows better generalization to longer contexts beyond training limits.
Granite 4.0 ditches positional encoding altogether, with testing already validating 128K-token performance and hinting at potential scalability into million-token territory — limited only by hardware, not model architecture.
Open Access and Enterprise Potential
Though IBM is clear that the Tiny Preview isn't ready for enterprise deployment just yet, it’s a clear invitation to developers.
Released under the Apache 2.0 license and hosted on Hugging Face, the model is designed to be accessible to GPU-limited builders. Upcoming support via platforms like Ollama and LMStudio will make local deployment even easier.
Granite 4.0 Tiny also continues a growing IBM trend: making cutting-edge LLMs practical, efficient, and open.
With toggleable “thinking mode,” no architectural limits on context length, and an eye toward both reasoning and inference speed, the Granite line is fast becoming one of the most interesting open-source LLM initiatives in the enterprise AI landscape.
More details — and likely a few surprises — are expected at IBM Think 2025. But one thing is already clear: Granite 4.0 Tiny is small in size, but big on ambition.















